


1. 前言
知识追踪(Knowledge Tracing,KT)的目标是根据学生过去的做题记录,估计学生当前的知识状态,并预测学生在下一道题上的作答表现。
传统的深度知识追踪模型通常把知识点作为建模对象。例如,只要两道题关联了相同的知识点,模型就可能把它们视为相似甚至等价的题目。
但在真实教学场景中,即使两道题关联相同的知识点,它们的难度、题型、表达方式和解题过程也可能完全不同。学生做完这些题后获得的知识增量也不一定相同。
QIKT,即 Question-centric Interpretable Knowledge Tracing,尝试解决两个问题:
如何在知识追踪中显式考虑具体题目的影响;
如何让深度知识追踪模型的预测结果具有一定的可解释性。
本文将从论文思想、数学结构和代码实现三个角度分析 QIKT。
2. QIKT 要解决什么问题
2.1 同质题目假设
许多知识追踪模型主要根据知识点建模。
假设题目 和 都属于知识点 ,模型可能认为它们对学生知识状态的影响基本相同。
这种假设可以写成:
其中 表示题目 所关联的知识点集合。
但实际情况是:
两道题可能难度不同;
对知识点的考查深度不同;
学生做对后的知识增量不同;
学生在两道题上的表现也可能不同。
因此,QIKT 不仅使用知识点信息,还显式加入题目 ID 的表示。
2.2 深度学习模型缺乏可解释性
LSTM、Transformer 等模型可以获得较好的预测效果,但隐藏状态通常很难直接解释。
例如,模型输出学生下一题答对概率为 0.72,但很难回答:
学生当前的知识掌握程度是多少?
这道题本身对预测有什么影响?
学生是因为掌握知识而答对,还是因为题目较简单?
当前预测主要受到哪一部分信息影响?
QIKT 将预测过程拆分为三个分数:
分别表示:
:题目中心的知识获取分数;
:一般知识状态分数;
:面对下一道题时的问题解决分数。
3. QIKT 的整体结构
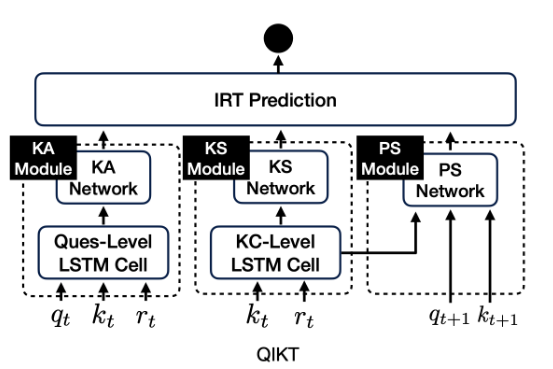
QIKT 主要由五个部分组成:
Interaction Encoder
Question-centric Knowledge Acquisition Module(KA)
Question-agnostic Knowledge State Module(KS)
Question-centric Problem Solving Module(PS)
IRT-based Prediction Layer
4. 交互编码
QIKT 同时建立题目级交互表示和知识点级交互表示。
设:
为第 个题目的嵌入;
为该题关联知识点的平均嵌入;
为作答结果。
如果一道题关联多个知识点。QIKT 并不会为每个知识点分别建立一条交互记录,而是先将该题关联的所有知识点嵌入进行平均,得到题目的综合知识点表示。
设题目 关联的知识点集合为 ,第 个知识点的嵌入为 ,则题目 的知识点表示为:
论文将其写成遍历全部知识点并使用指示函数筛选的形式:
4.1 题目级交互表示
题目和知识点首先拼接:
然后根据回答结果放入不同通道。
当回答正确时:
当回答错误时:
这样可以让模型区分“在某道题上回答正确”和“在某道题上回答错误”。
4.2 知识点级交互表示
KS 模块不关注具体题目,只关注知识点和回答。
当回答正确时:
当回答错误时:
5. Question-centric Knowledge Acquisition Module
KA 模块用于描述:
学生在完成某一道具体题目后,获得了怎样的知识变化。
QIKT 的 KA 模块同时考虑:
当前题目的题目表示;
当前题目关联的知识点表示;
学生在当前题目上的作答结果;
学生之前的题目级知识状态。
其目标是学习一种对具体题目敏感的知识状态表示。
其输入包含:
具体题目 ;
题目关联知识点 ;
学生的回答结果 。
通过之前的交互编码,使得对于同一道题,正确和错误也会形成不同的交互表示 。
5.1 LSTM 更新题目级知识状态
KA 模块使用一个 LSTM 对学生的题目级知识状态进行更新。
其中 是学生在第 次交互后的题目级知识状态。
论文展开写出了 LSTM 的门控计算过程:
输入门:
遗忘门:
输出门:
记忆单元:
汇总了学生到当前时刻为止的题目交互历史,并且保留了具体题目带来的差异。
由于 只是一个高维隐藏向量,不能直接解释为学生的知识掌握度。论文还需要通过一个知识获取网络,将其转换为标量分数 。
5.2 计算知识获取分数
论文使用两层非线性变换,将题目级状态 投影到题目空间:
其中:
是隐藏状态维度, 是题库中的题目总数,因此: 。
也就是说,模型将学生当前的题目级认知状态映射到一个 维题目空间,每一维对应题库中的一道题。
随后,模型使用可学习权重 对各题目维度进行加权:
最后通过 Sum Pooling,将所有题目维度相加:
最终得到的: 是一个标量。
它表示学生在完成前 次题目交互后,模型估计出的题目中心知识获取分数。
6. Question-agnostic Knowledge State Module
6.1 为什么需要 KS 模块
KA 模块同时使用题目、知识点和作答结果,因此能够捕获不同题目带来的细粒度认知变化。
但是,在真实答题过程中,学生可能出现两类特殊情况:
Guess:学生并未真正掌握知识,但通过猜测回答正确;
Slip:学生已经掌握知识,但因为粗心等原因回答错误。
如果模型只依赖 KA 模块,那么某一次偶然的正确或错误可能使题目级状态发生较大变化,从而导致模型对单次交互过于敏感。
因此,QIKT 增加了 KS 模块作为补充,用于学习更加稳定、更加一般化的知识状态。
KA 与 KS 的侧重点可以概括为:
6.2 使用 LSTM 更新一般知识状态
论文使用另一个独立的 LSTM 更新学生的知识状态。
设学生在时刻 的一般知识状态为 ,当前知识点级交互表示为 ,则:
其中: 表示学生完成第 次交互后的一般知识状态。
论文正文没有再次完整展开 KS-LSTM 的门控公式,因为它与 KA 模块中的 LSTM 更新过程基本相同。二者的主要区别不是 LSTM 结构,而是输入信息不同。
因此:
是题目敏感的状态;
是题目无关的一般知识状态。
6.3 将知识状态投影到知识点空间
LSTM 得到的 是一个隐藏向量,还不能直接解释为知识掌握分数。
论文首先对其进行两层非线性变换:
然后映射到知识点空间:
论文给出的参数维度为:
其中:
是 LSTM 隐藏状态维度;
是题库中的知识点总数。
因此: 这意味着模型将学生的隐藏状态投影到了知识点空间:
每一维对应一个知识点方向上的状态响应。
6.5 计算知识掌握分数
模型使用可学习向量 对知识点空间中的不同维度进行加权:
其中: ,符号 表示逐元素乘法。
最后,通过 Sum Pooling 对所有知识点维度求和:
因此,论文中的完整公式为:
最终得到: 即一个标量形式的知识掌握分数。
7. Question-centric Problem Solving Module
7.1 为什么需要 PS 模块
学生能否正确回答一道题,不仅取决于是否掌握相关知识点,还与题目本身有关。
即使两道题考查相同的知识点,它们仍然可能具有不同的:
题目难度;
区分度;
表达形式;
解题步骤;
对知识综合运用能力的要求。
因此,“掌握某个知识点”并不意味着学生一定能正确回答所有与该知识点相关的题目。
KS 模块主要回答:
学生当前对相关知识掌握得怎么样?
而 PS 模块进一步回答:
面对下一道具体题目,学生能否将已经掌握的知识应用出来?
因此,PS 模块同时考虑学生当前知识状态和下一道题的具体信息。
7.2 构造下一题的问题解决表示
设学生完成前 次交互后,KS 模块得到的一般知识状态为:
下一道题为 ,其题目嵌入为:
下一道题关联的知识点平均嵌入为:
PS 模块将这三个向量拼接:
由于三个向量的维度都是 ,因此:
7.3 计算知识应用分数
得到 后,论文使用两层全连接网络提取问题解决特征:
然后进行第二次非线性变换:
最后使用一个线性层将高维表示压缩成标量:
将三步合并后,论文公式为:
其中:
最终得到:
也就是说, 是一个标量。
论文将 称为学生在题目 上的知识应用分数。
它反映的是:
在学生当前知识状态下,面对下一道具体题目时,将已有知识应用到该题上的倾向。
8. Interpretable Prediction Layer
前面的三个模块分别得到三个分数:
:KA 模块输出的题目中心知识获取分数;
:KS 模块输出的一般知识掌握分数;
:PS 模块输出的下一题知识应用分数。
QIKT 不再使用一个复杂的神经网络将三个分数进行融合,而是采用一种基于 IRT 思想的简单加法形式:
其中:
表示学生回答下一道题 正确的预测概率;
8.1 三个分数分别表示什么
直观地说,模型预测学生能否回答正确时,同时考虑:
学生通过过去的具体题目获得了多少知识;
学生当前总体掌握了多少知识;
学生是否能将已有知识应用到下一道具体题目中。
当三个分数的和较大时: 表示模型认为学生更可能回答正确。
当三个分数的和较小时: 表示模型认为学生更可能回答错误。
8.2 为什么说这一层具有可解释性
普通深度知识追踪模型通常直接执行:
最终预测由一个高维隐藏状态经过复杂网络得到,很难说明预测结果具体受哪些认知因素影响。
QIKT 可以在分析某一次预测时,可以分别观察:
从而判断最终预测更可能受到哪一部分因素的影响。
例如:
较高,说明学生总体知识状态较好;
较低,说明学生虽然掌握相关知识,但可能难以应用到当前题目;
较低,说明题目级交互历史所体现出的知识获取效果较弱。
需要注意的是,这三个分数是模型学习得到的潜在认知分数,并不是可以直接观测到的真实心理测量值。
8.3 为什么最终层不加入可学习参数
论文特别说明,最终预测函数中不加入额外的可学习参数。
也就是说,论文没有使用:
而是直接使用:
这样做的原因是,如果再加入可学习权重和复杂非线性变换,最终预测虽然可能更加灵活,但三个内部得分的含义会变得更加难以分析。
采用直接相加的方式,可以让预测结构保持简单。
因此,这里更准确的说法是:
QIKT 使用了基于 IRT 思想的加性预测形式,而不是完整复现传统 IRT 中的所有参数。
9. Optimization of QIKT
9.1 最终预测损失
QIKT 首先使用二元交叉熵损失监督最终预测结果。
设真实作答结果为:
模型预测学生答对的概率为:
则 IRT 预测层的损失为:
当学生实际回答正确,即 时:
模型预测的正确概率越接近 1,损失越小。
当学生实际回答错误,即时:
模型预测的正确概率越接近 0,损失越小。
9.2 为什么还需要辅助损失
如果模型只监督最终结果:
那么只需要保证三个分数的和能够正确预测即可。
三者相加仍然可以得到合理结果,但单独观察每一个分数时,其判别能力可能不够稳定。
因此,论文不仅监督最终预测,还要求三个内部得分分别具有一定的预测能力。
对于任意内部得分 ,定义辅助损失:
其中 可以分别取:
因此,三个辅助损失分别为:
这些损失分别要求:
KA 分数能够区分正确和错误;
KS 分数能够区分正确和错误;
PS 分数能够区分正确和错误。
9.3 QIKT 的完整损失函数
最终优化目标为:
其中:
监督最终预测概率;
监督知识获取分数;
监督知识掌握分数;
监督知识应用分数;
是用于控制辅助损失强度的超参数。
当 时: 模型只优化最终预测结果,不直接约束三个内部得分。
当 较大时,模型会更重视三个模块各自的判别能力,但如果设置过大,也可能削弱最终联合预测的优化效果。
QIKT 论文学习:基于题目中心认知表示的可解释知识追踪
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
评论交流
欢迎留下你的想法