


一、A* 算法解决什么问题?
A* 是一种 启发式搜索算法。
它常用于解决:
网格地图最短路径
八数码、十五数码问题
状态空间搜索
第 K 短路
迷宫寻路
游戏 AI 路径规划
普通 BFS 或 Dijkstra 搜索时,会比较“盲目”地扩展节点。
而 A* 的核心思想是:
不仅考虑当前已经走了多远,还要估计从当前位置到终点还需要走多远。
因此,A* 会优先搜索那些“看起来更有希望到达终点”的状态。
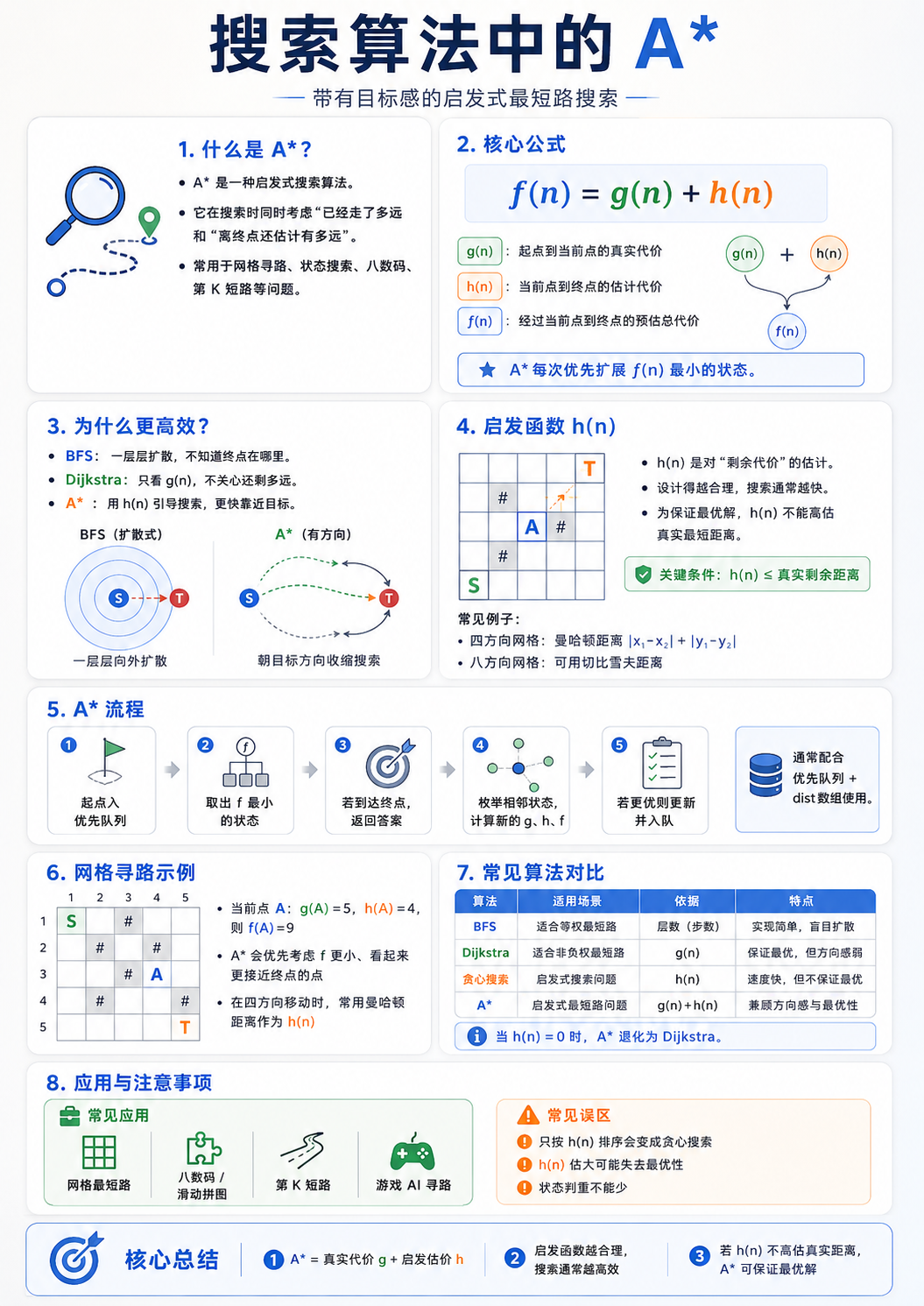
二、从 BFS / Dijkstra 引出 A*
1. BFS 的局限
BFS 适合解决边权相同的最短路问题。
例如在一个网格中,每走一步代价都是 1,那么 BFS 可以求出最短路径。
但是 BFS 的问题是:
它不知道终点在哪里,只会一层一层向外扩展。
假设起点在左上角,终点在右下角,BFS 会向所有方向扩散,很多明显不靠近终点的状态也会被搜索。
2. Dijkstra 的局限
Dijkstra 可以解决非负权图最短路问题。
它每次选择当前距离起点最近的点进行扩展。
但是 Dijkstra 也有一个问题:
它只关心从起点到当前点的距离,不关心当前点离终点还有多远。
所以在目标明确的搜索问题中,Dijkstra 也可能搜索大量无关状态。
3. A* 的改进
A* 在 Dijkstra 的基础上加入了一个“估计值”。
对于每个状态 n,A* 计算:
f(n) = g(n) + h(n)其中:
g(n):从起点到当前状态 n 的真实代价
h(n):从当前状态 n 到终点的估计代价
f(n):经过当前状态 n 到达终点的估计总代价A* 每次优先扩展 f(n) 最小的状态。
三、A* 的核心公式
A* 最重要的公式就是:
f(n) = g(n) + h(n)可以把它理解成:
已经付出的代价 + 预计还要付出的代价 = 这条路线的预估总代价例如在网格中:
起点 S 到当前点 A 已经走了 7 步
当前点 A 到终点 T 估计还需要 10 步
那么:
g(A) = 7
h(A) = 10
f(A) = 17A* 会优先选择 f 值较小的点继续搜索。
四、启发函数 h(n)
A* 的灵魂在于启发函数 h(n)。
h(n) 用来估计当前状态到终点的距离。
1. h(n) 的常见设计
在网格最短路中,常见启发函数有:
曼哈顿距离
适用于只能上下左右四个方向移动的网格。
h(x, y) = |x - targetX| + |y - targetY|例如:
当前点:(2, 3)
终点:(6, 8)
h = |2 - 6| + |3 - 8|
= 4 + 5
= 9欧几里得距离
适用于可以任意方向移动的场景。
h(x, y) = sqrt((x - targetX)^2 + (y - targetY)^2)切比雪夫距离
适用于可以八个方向移动,并且斜向移动代价和直线移动代价相同的网格。
h(x, y) = max(|x - targetX|, |y - targetY|)五、启发函数的关键要求
在算法竞赛中,A* 想要保证最优解,启发函数通常需要满足:
1. 不能高估真实代价
也就是说:
h(n) <= 当前点 n 到终点的真实最短距离这叫做 可采纳性,英文叫 admissible。
简单理解:
h(n) 可以估小,但不能估大。
例如在四方向网格中,曼哈顿距离就是一个合法的启发函数。
因为从当前点到终点,至少要走横向距离加纵向距离那么多步。
2. 为什么不能高估?
假设某个状态真实到终点只需要 5 步,但你的估价函数给它估成 100。
那么 A* 可能会认为这条路很差,从而不优先搜索它,甚至错过最优解。
所以:
h(n) 估小一点没关系
h(n) 估大了可能出错六、A* 算法流程
可以这样描述:
把起点加入优先队列。
每次取出
f = g + h最小的状态。如果当前状态是终点,返回答案。
否则枚举它的下一个状态。
计算新状态的
g、h、f。如果新状态可以被更新,就加入优先队列。
重复以上过程。
伪代码:
A*(start, target):
创建优先队列 pq
dist[start] = 0
pq.push(start, f = h(start))
while pq 不为空:
cur = pq.poll()
if cur 是 target:
return dist[cur]
for next in cur 的所有邻接状态:
newG = dist[cur] + cost(cur, next)
if newG < dist[next]:
dist[next] = newG
f = newG + h(next)
pq.push(next, f)
return 无解七、A* 和 Dijkstra 的关系
A* 可以看成是 Dijkstra 的增强版。
Dijkstra 的排序依据是:g(n)
A* 的排序依据是:g(n) + h(n)
当:h(n) = 0 时,A* 就退化成了 Dijkstra。
所以可以这样理解:
Dijkstra:只看已经走了多远
A*:既看已经走了多远,也看离终点还有多远八、A* 和其他搜索算法的区别
需要强调一点:
贪心搜索只看 h(n),可能很快,但不一定最优。
A* 同时看 g(n) 和 h(n),在合适条件下可以保证最优。
九、网格最短路中的 A*
假设有一个二维网格:
0 表示可以走
1 表示障碍物要求从左上角走到右下角,每次可以上下左右移动一步。
普通 BFS 可以做,但 A* 可以用曼哈顿距离来加速搜索。
状态设计
每个状态包含:
x:当前行
y:当前列
g:从起点到当前位置的真实距离
f:g + h,预估总代价启发函数:
h(x, y) = Math.abs(x - targetX) + Math.abs(y - targetY)十、代码模板:网格 A*
import java.util.*;
public class AStarGrid {
static class Node {
int x;
int y;
int g; // 起点到当前点的真实代价
int f; // g + h
Node(int x, int y, int g, int f) {
this.x = x;
this.y = y;
this.g = g;
this.f = f;
}
}
static int[][] dirs = {
{1, 0},
{-1, 0},
{0, 1},
{0, -1}
};
public static int aStar(int[][] grid) {
int m = grid.length;
int n = grid[0].length;
int startX = 0;
int startY = 0;
int targetX = m - 1;
int targetY = n - 1;
if (grid[startX][startY] == 1 || grid[targetX][targetY] == 1) {
return -1;
}
int[][] dist = new int[m][n];
for (int[] row : dist) {
Arrays.fill(row, Integer.MAX_VALUE);
}
PriorityQueue<Node> pq = new PriorityQueue<>((a, b) -> a.f - b.f);
dist[startX][startY] = 0;
int startH = heuristic(startX, startY, targetX, targetY);
pq.offer(new Node(startX, startY, 0, startH));
while (!pq.isEmpty()) {
Node cur = pq.poll();
// 如果当前节点不是最优记录,跳过
if (cur.g > dist[cur.x][cur.y]) {
continue;
}
// 第一次从优先队列中弹出终点时,就是最短距离
if (cur.x == targetX && cur.y == targetY) {
return cur.g;
}
for (int[] dir : dirs) {
int nx = cur.x + dir[0];
int ny = cur.y + dir[1];
if (nx < 0 || nx >= m || ny < 0 || ny >= n) {
continue;
}
if (grid[nx][ny] == 1) {
continue;
}
int newG = cur.g + 1;
if (newG < dist[nx][ny]) {
dist[nx][ny] = newG;
int h = heuristic(nx, ny, targetX, targetY);
int f = newG + h;
pq.offer(new Node(nx, ny, newG, f));
}
}
}
return -1;
}
// 曼哈顿距离
private static int heuristic(int x, int y, int targetX, int targetY) {
return Math.abs(x - targetX) + Math.abs(y - targetY);
}
public static void main(String[] args) {
int[][] grid = {
{0, 0, 0, 0},
{1, 1, 0, 1},
{0, 0, 0, 0},
{0, 1, 1, 0}
};
System.out.println(aStar(grid));
}
}十一、代码细节解释
1. 为什么用优先队列?
因为 A* 每次要取出 f = g + h 最小的状态。
所以需要使用优先队列:
PriorityQueue<Node> pq = new PriorityQueue<>((a, b) -> a.f - b.f);2. dist 数组的作用
dist[x][y] 表示:
从起点到 (x, y) 的当前最短真实距离只有当发现更短路径时,才更新:
if (newG < dist[nx][ny]) {
dist[nx][ny] = newG;
}3. 为什么要跳过旧状态?
优先队列中可能存在同一个点的多个版本。
例如第一次到达 (x, y) 的距离是 10,后来又找到一条距离为 7 的路径。
那么距离为 10 的旧状态还在队列里。
所以需要:
if (cur.g > dist[cur.x][cur.y]) {
continue;
}这和 Dijkstra 的写法类似。
十二、A* 的正确性条件
当启发函数 h(n) 不高估从 n 到终点的真实最短距离时,A* 可以保证找到最优解。
也就是:
h(n) <= realDistance(n, target)例如四方向网格中:
h(n) = 曼哈顿距离就是合法的。
因为不管怎么走,从 (x, y) 到 (targetX, targetY),至少要走:
|x - targetX| + |y - targetY|这么多步。
十三、A* 的复杂度
理论上,A* 的最坏时间复杂度仍然可能接近 Dijkstra。
可以写成:
时间复杂度:O(E log V)
空间复杂度:O(V)其中:
V:状态数量
E:状态转移数量但是 A* 的实际表现很依赖启发函数。
如果 h(n) 设计得好,它会大幅减少搜索状态。
如果 h(n) 设计得很差,例如永远等于 0,那么 A* 就退化成 Dijkstra。
十四、A* 的常见竞赛模型
1. 网格最短路
典型场景:给定地图、障碍物、起点、终点,求最短路径。
启发函数通常用:曼哈顿距离
适合:
只能上下左右移动
每一步代价相同2. 八数码问题
八数码是 A* 的经典应用。
状态是一个 3×3 棋盘,例如:
1 2 3
4 0 6
7 5 8其中 0 表示空格。
目标状态可能是:
1 2 3
4 5 6
7 8 0常见启发函数:
所有数字当前位置到目标位置的曼哈顿距离之和例如数字 5 当前在 (2, 1),目标位置在 (1, 1),那么它的距离是 1。
把所有数字的距离加起来,就是当前状态的估价函数。
h(state) = 每个数字到目标位置的曼哈顿距离之和这个估价函数不会高估真实步数,因此适合作为 A* 的启发函数。
3. 第 K 短路
A* 在竞赛中还有一个非常经典的应用:求从 s 到 t 的第 K 短路
常见做法:
先在反图上从终点
t跑一次 Dijkstra。得到每个点到终点的最短距离
h[u]。然后从起点
s开始做 A*。每次按照
g[u] + h[u]排序。当终点第 K 次出队时,答案就是第 K 短路长度。
这里的:
g[u]:从起点 s 到当前点 u 的路径长度
h[u]:从当前点 u 到终点 t 的最短距离因为 h[u] 是真实最短距离,所以它一定是合法估价函数。
4. IDA*
IDA* 可以看成是:迭代加深搜索 + A* 估价函数
它常用于状态空间巨大,但内存不够存大量状态的问题。
例如:
八数码
十五数码
魔板问题
一些拼图类问题IDA* 的核心是限制:
g(n) + h(n) <= depthLimit如果超过限制,就剪枝。
十五、A* 常见错误
错误 1:h(n) 估大了
如果启发函数高估了真实距离,A* 可能得不到最优解。
错误例子:
真实剩余距离是 5
h(n) 却返回 100这样会让算法错误地认为这个状态很差。
错误 2:把 A* 当成一定比 BFS 快
A* 不一定总比 BFS 快。
它是否更快,取决于启发函数是否有效。
如果启发函数很弱:h(n) = 0
那它就退化成 Dijkstra。
如果边权全是 1,那么这种情况下甚至可能不如普通 BFS 简洁。
错误 3:没有处理重复状态
在状态搜索问题中,经常会出现同一个状态被多次访问。
例如八数码中:A -> B -> A
如果不判重,就可能无限搜索。
因此一般需要:
dist 数组
HashMap
HashSet来记录状态是否访问过,或者当前状态的最优代价。
错误 4:优先队列排序只看 h
如果只按照 h(n) 排序,那就变成了贪心搜索。
贪心搜索不保证最优。
A* 必须按照:f(n) = g(n) + h(n) 排序。
错误 5:边权有负数
A* 通常用于非负边权图。
如果图中存在负边,Dijkstra 本身就不适用,A* 也不能直接套用。
搜索算法进阶:A* 算法详解
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
评论交流
欢迎留下你的想法