


一、文章大纲
1. DFS 搜索顺序是什么?
先说明 DFS 的本质。
DFS 不是简单地“递归往下走”,而是在一棵隐式的搜索树上进行遍历。
例如排列问题:从 1 ~ n 中选数,组成一个排列
搜索树可以理解为:
第 0 层:还没有选任何数
第 1 层:选择第 1 个位置的数字
第 2 层:选择第 2 个位置的数字
第 3 层:选择第 3 个位置的数字
...DFS 的搜索顺序就是决定:
每一层搜索什么?
每一层有哪些选择?
这些选择按照什么顺序枚举?核心定义:
DFS 搜索顺序,就是我们在搜索树中设计“状态扩展顺序”和“分支枚举顺序”的方式。
2. 为什么搜索顺序很重要?
搜索顺序不仅影响输出顺序,还会影响效率。
2.1 影响答案输出顺序
比如生成排列时,如果每一层从小到大枚举:
for (int i = 1; i <= n; i++)输出结果通常是字典序靠前的排列先出现。
如果从大到小枚举:
for (int i = n; i >= 1; i--)输出顺序就会相反。
2.2 影响剪枝效率
在很多搜索题中,搜索树非常大。
同样是 DFS,如果先搜索更容易失败的分支,就能更早剪枝。
例如数独:
如果随便找一个空格填数,可能分支很多;
如果优先找可填数字最少的空格,搜索规模会大幅减少。这就是典型的搜索顺序优化。
2.3 影响代码设计
不同搜索顺序会导致 DFS 参数不同。
例如:
排列型搜索:dfs(pos)
表示当前正在填第 pos 个位置。
组合型搜索:dfs(start, path)
表示从 start 开始继续选数。
棋盘型搜索:dfs(row)
表示当前正在处理第 row 行。
状态压缩型搜索:dfs(state)
表示当前集合状态是 state。
所以,设计搜索顺序之前,最好先想清楚:DFS 的每一层代表什么?
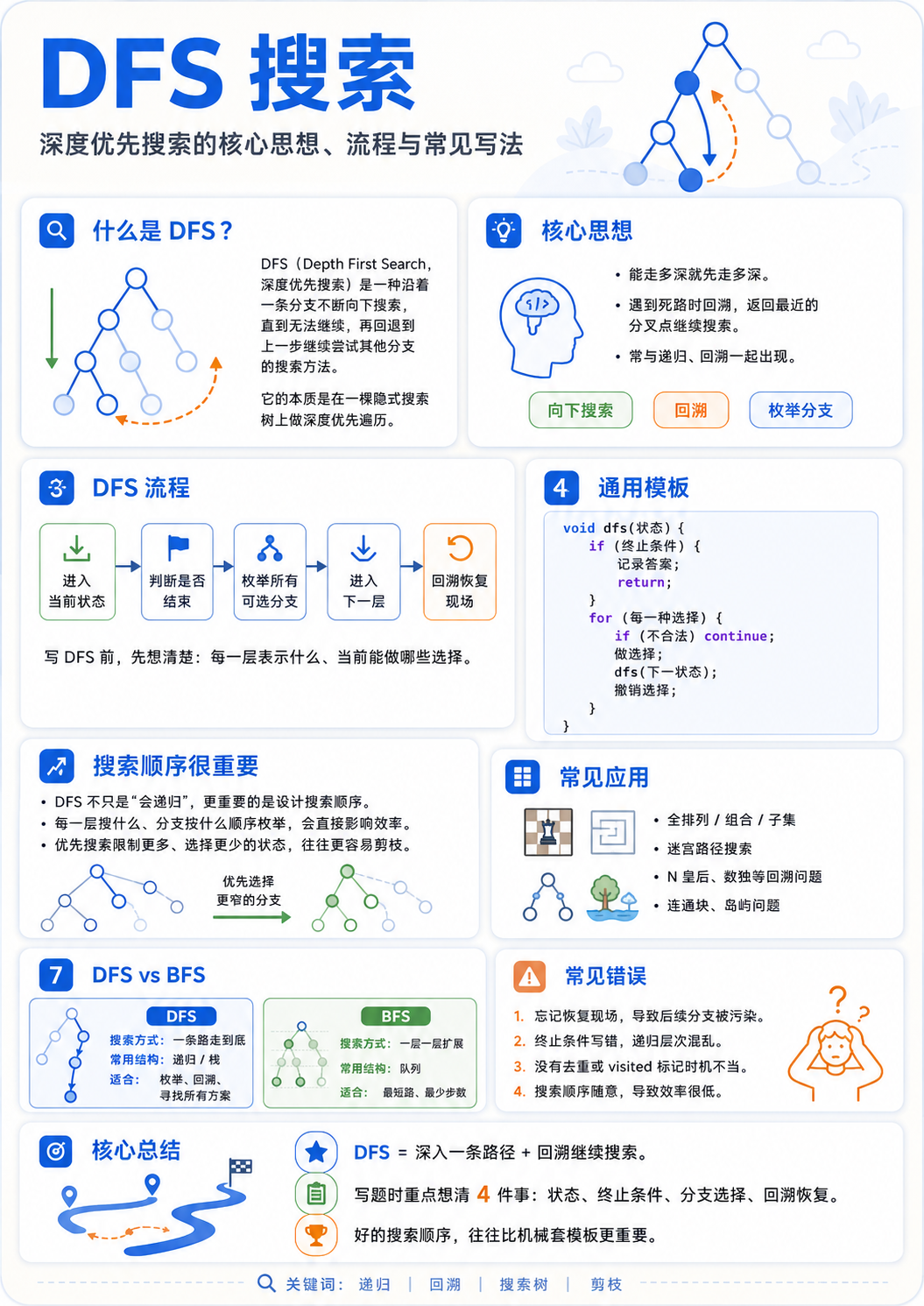
二、DFS 搜索树的基本结构
DFS 通常包含四个部分:
1. 当前状态
2. 终止条件
3. 枚举选择
4. 恢复现场Java 模板:
void dfs(当前状态) {
if (到达终止条件) {
记录答案;
return;
}
for (枚举当前可以选择的分支) {
if (不合法) continue;
做出选择;
dfs(下一层状态);
撤销选择;
}
}搜索顺序主要体现在两个地方:
第一,每一层 DFS 表示什么状态;
第二,for 循环按照什么顺序枚举分支。
三、常见 DFS 搜索顺序模型
1. 排列型搜索顺序
问题描述
给定 1 ~ n,输出所有排列。
例如 n = 3:
1 2 3
1 3 2
2 1 3
2 3 1
3 1 2
3 2 1搜索顺序设计
每一层表示:当前正在填写排列中的第 pos 个位置
搜索树结构:
第 0 层:填第 0 个位置
第 1 层:填第 1 个位置
第 2 层:填第 2 个位置
...每一层可以选择一个还没有用过的数字。
Java 代码
import java.util.*;
public class Main {
static int n;
static int[] path;
static boolean[] used;
public static void main(String[] args) {
n = 3;
path = new int[n];
used = new boolean[n + 1];
dfs(0);
}
static void dfs(int pos) {
if (pos == n) {
for (int x : path) {
System.out.print(x + " ");
}
System.out.println();
return;
}
for (int i = 1; i <= n; i++) {
if (used[i]) continue;
path[pos] = i;
used[i] = true;
dfs(pos + 1);
used[i] = false;
}
}
}细节解释
这里的搜索顺序是:
先确定第 0 个位置
再确定第 1 个位置
再确定第 2 个位置
...每一层从小到大尝试数字,所以结果按照字典序输出。
如果改成:for (int i = n; i >= 1; i--)
那么输出顺序就会变成从大到小。
2. 组合型搜索顺序
问题描述
从 1 ~ n 中选择 k 个数,输出所有组合。
例如 n = 5, k = 3:
1 2 3
1 2 4
1 2 5
1 3 4
1 3 5
1 4 5
2 3 4
2 3 5
2 4 5
3 4 5搜索顺序设计
组合和排列不同。
排列关心顺序:1 2 3 和 1 3 2 是不同排列
组合不关心顺序:1 2 3 和 1 3 2 是同一个组合
所以组合型搜索必须避免重复。
常见做法是使用 start 参数,保证后面选的数字一定比前面大。
Java 代码
import java.util.*;
public class Main {
static int n = 5;
static int k = 3;
static List<Integer> path = new ArrayList<>();
public static void main(String[] args) {
dfs(1);
}
static void dfs(int start) {
if (path.size() == k) {
System.out.println(path);
return;
}
for (int i = start; i <= n; i++) {
path.add(i);
dfs(i + 1);
path.remove(path.size() - 1);
}
}
}搜索顺序解释
这里的搜索顺序是:
从小到大选数
每次只能从当前数字后面继续选比如已经选了 2,后面只能选:3、4、5
不能再回头选 1,否则会出现重复组合。
小优化:可行性剪枝
如果剩余数字数量不够,就没必要继续搜索。
当前还需要选择:
k - path.size()剩余可选数字数量:n - i + 1
所以循环上界可以优化成:
for (int i = start; i <= n - (k - path.size()) + 1; i++)完整写法:
static void dfs(int start) {
if (path.size() == k) {
System.out.println(path);
return;
}
for (int i = start; i <= n - (k - path.size()) + 1; i++) {
path.add(i);
dfs(i + 1);
path.remove(path.size() - 1);
}
}这个剪枝虽然简单,但能减少无效搜索。
3. 子集型搜索顺序
问题描述
给定 1 ~ n,输出所有子集。
例如 n = 3:
[]
[1]
[2]
[3]
[1, 2]
[1, 3]
[2, 3]
[1, 2, 3]搜索顺序一:每个数选或不选
每一层表示:当前考虑第 u 个数
对于每个数都有两个选择:选 / 不选
Java 代码:
import java.util.*;
public class Main {
static int n = 3;
static List<Integer> path = new ArrayList<>();
public static void main(String[] args) {
dfs(1);
}
static void dfs(int u) {
if (u > n) {
System.out.println(path);
return;
}
// 不选 u
dfs(u + 1);
// 选 u
path.add(u);
dfs(u + 1);
path.remove(path.size() - 1);
}
}搜索顺序解释
这个 DFS 的搜索树是二叉树:
第 1 层:选不选 1
第 2 层:选不选 2
第 3 层:选不选 3这种写法的优点是逻辑非常清晰。
搜索顺序二:枚举下一个选哪个数
也可以写成组合型风格:
static void dfs(int start) {
System.out.println(path);
for (int i = start; i <= n; i++) {
path.add(i);
dfs(i + 1);
path.remove(path.size() - 1);
}
}这种写法每进入一个状态就输出当前路径。
它的搜索顺序是:
先输出当前集合
再尝试继续加入更大的数字4. 棋盘型搜索顺序
棋盘问题是 DFS 搜索顺序中非常经典的一类。
典型问题包括:
N 皇后
数独
迷宫路径
单词搜索4.1 N 皇后:按行搜索
问题描述
在 n × n 棋盘上放置 n 个皇后,使得任意两个皇后不能互相攻击。
皇后之间不能在:
同一行
同一列
同一条主对角线
同一条副对角线搜索顺序设计
最自然的搜索顺序是:每一行放一个皇后
也就是:
第 0 层:决定第 0 行皇后放在哪一列
第 1 层:决定第 1 行皇后放在哪一列
第 2 层:决定第 2 行皇后放在哪一列
...这样可以天然保证每一行只有一个皇后。
Java 代码
import java.util.*;
public class Main {
static int n = 4;
static char[][] board;
static boolean[] col;
static boolean[] diag;
static boolean[] antiDiag;
public static void main(String[] args) {
board = new char[n][n];
for (int i = 0; i < n; i++) {
Arrays.fill(board[i], '.');
}
col = new boolean[n];
diag = new boolean[2 * n];
antiDiag = new boolean[2 * n];
dfs(0);
}
static void dfs(int row) {
if (row == n) {
printBoard();
System.out.println();
return;
}
for (int c = 0; c < n; c++) {
int d = row - c + n;
int ad = row + c;
if (col[c] || diag[d] || antiDiag[ad]) continue;
board[row][c] = 'Q';
col[c] = diag[d] = antiDiag[ad] = true;
dfs(row + 1);
board[row][c] = '.';
col[c] = diag[d] = antiDiag[ad] = false;
}
}
static void printBoard() {
for (int i = 0; i < n; i++) {
System.out.println(new String(board[i]));
}
}
}关键细节
为什么按行搜索比逐格搜索更好?
如果逐格搜索,每个格子都要考虑:放皇后 / 不放皇后
搜索空间大约是:
如果按行搜索,每一行只需要选择一列,搜索空间大约是:
虽然仍然很大,但已经少了很多无效分支。
这说明:
好的搜索顺序可以减少状态数量。
4.2 迷宫搜索:按方向顺序搜索
问题描述
从起点走到终点,输出路径或者判断是否可达。
搜索顺序通常体现在方向数组中。
例如:
int[] dx = {-1, 0, 1, 0};
int[] dy = {0, 1, 0, -1};表示搜索顺序是:上、右、下、左
如果改成:
int[] dx = {1, 0, -1, 0};
int[] dy = {0, 1, 0, -1};搜索顺序就变成:下、右、上、左
Java 代码
public class Main {
static int n = 4;
static int m = 4;
static int[][] grid = {
{0, 0, 1, 0},
{1, 0, 1, 0},
{0, 0, 0, 0},
{0, 1, 1, 0}
};
static boolean[][] visited = new boolean[n][m];
static int[] dx = {-1, 0, 1, 0};
static int[] dy = {0, 1, 0, -1};
public static void main(String[] args) {
boolean ok = dfs(0, 0);
System.out.println(ok);
}
static boolean dfs(int x, int y) {
if (x == n - 1 && y == m - 1) {
return true;
}
visited[x][y] = true;
for (int i = 0; i < 4; i++) {
int nx = x + dx[i];
int ny = y + dy[i];
if (nx < 0 || nx >= n || ny < 0 || ny >= m) continue;
if (grid[nx][ny] == 1) continue;
if (visited[nx][ny]) continue;
if (dfs(nx, ny)) {
return true;
}
}
return false;
}
}注意点
如果只是判断是否存在路径,DFS 找到一条路径就可以返回。
但是如果要搜索所有路径,就不能提前 return true,而是要继续回溯。
四、搜索顺序优化:先搜更容易失败的状态
很多 DFS 超时,并不是因为 DFS 本身写错了,而是搜索顺序太随意。
一个重要原则是:
优先搜索限制条件更多、选择更少的状态。
这样可以更早发现无解分支,从而减少搜索规模。
1. 数独中的搜索顺序优化
普通搜索顺序
最简单的数独 DFS 是按格子顺序搜索:
从左到右
从上到下
遇到空格就尝试填 1 ~ 9但是这种方式不一定高效。
有些空格可以填很多数字,有些空格只能填一个数字。
如果先填选择多的空格,搜索树会非常大。
更好的搜索顺序
每次选择:当前可填数字最少的空格
这叫做:最小候选集优先
也可以理解为:先处理最难填的位置
比如:
A 空格可以填 1, 2, 3, 4, 5
B 空格只能填 7应该先填 B。
因为 B 如果填不了,马上就能剪枝。
2. 通用原则:搜索顺序和剪枝配合
搜索顺序和剪枝通常是一起使用的。
例如:先排序、再 DFS
常见场景:
从大到小搜索
优先选择约束强的点
优先选择数量少的分支
优先尝试更可能成功的方案比如装箱问题、小猫爬山问题中,通常会先把物品重量从大到小排序。
原因是:
大物品更难放
先放大物品可以更早暴露冲突如果先放小物品,可能前面看起来都能放,后面遇到大物品才发现放不下,浪费大量搜索。
五、搜索顺序设计的常见思考方法
做 DFS 题时,可以按照下面几个问题思考。
1. 每一层 DFS 表示什么?
这是最重要的问题。
常见设计有:
每一层填一个位置
每一层选择一个数字
每一层处理一行
每一层处理一个物品
每一层处理一个空格
每一层处理一个状态例如:
排列问题:每一层填排列中的一个位置
组合问题:每一层决定下一个选择哪个数字
N 皇后:每一层处理一行
数独:每一层处理一个空格
2. 当前状态需要保存什么?
常见状态包括:
当前位置 pos
当前路径 path
哪些数字已经使用 used
当前总和 sum
当前棋盘 board
当前答案数量 ans
当前已经选择的数量 cntDFS 参数不要乱写,要围绕“搜索顺序”设计。
3. 当前有哪些选择?
也就是 for 循环枚举什么。
例如:
排列问题:
for (int i = 1; i <= n; i++)组合问题:
for (int i = start; i <= n; i++)N 皇后:
for (int c = 0; c < n; c++)迷宫问题:
for (int i = 0; i < 4; i++)4. 分支按照什么顺序尝试?
这会影响效率。
常见策略:
从小到大枚举:适合要求字典序输出
从大到小枚举:适合先处理更难的元素
候选数量少的先枚举:适合约束满足问题
更可能成功的先枚举:适合快速找到一个可行解
更可能失败的先枚举:适合快速剪枝六、常见错误总结
1. 忘记恢复现场
错误示例:
path.add(i);
dfs(i + 1);
// 忘记 path.remove(path.size() - 1)这样会导致后续分支受到前一个分支的影响。
正确写法:
path.add(i);
dfs(i + 1);
path.remove(path.size() - 1);2. 组合问题没有使用 start
错误写法:
for (int i = 1; i <= n; i++) {
path.add(i);
dfs();
path.remove(path.size() - 1);
}这样会产生大量重复结果。
组合问题应该写成:
for (int i = start; i <= n; i++) {
path.add(i);
dfs(i + 1);
path.remove(path.size() - 1);
}3. visited 标记时机错误
迷宫 DFS 中,通常进入节点后标记:
visited[x][y] = true;如果搜索所有路径,退出时要恢复:
visited[x][y] = false;如果只是判断连通性,通常不需要恢复。
所以要区分:
求是否存在路径:visited 不恢复也可以
求所有路径:visited 通常需要恢复4. 递归终止条件写错
排列问题的终止条件是:
if (pos == n)组合问题的终止条件是:
if (path.size() == k)棋盘按行搜索的终止条件是:
if (row == n)终止条件必须和“每一层的含义”保持一致。
七、总结
DFS 的难点不只是会写递归模板,而是要学会设计搜索顺序。
一个好的搜索顺序,能够让搜索树更清晰,也能让剪枝更有效。
做 DFS 题时,应该先想清楚:每一层代表什么,当前有哪些选择,选择之后如何进入下一层,以及回溯时如何恢复现场。
通用思考框架:
1. 当前 DFS 的每一层表示什么?
2. 当前状态需要保存哪些信息?
3. 当前有哪些选择?
4. 这些选择按照什么顺序枚举?
5. 哪些分支可以提前剪掉?
6. 递归结束后是否需要恢复现场?DFS 中的搜索顺序
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
评论交流
欢迎留下你的想法