


一、引入:为什么需要双向广搜?
1. 从普通 BFS 说起
普通 BFS 常用于求:
无权图中的最短路问题。
比如:
从起点 start 出发,每次扩展一步,直到遇到终点 target。普通 BFS 的特点是:
一层一层向外扩展
第一次到达终点时,路径一定最短但是当搜索空间很大时,普通 BFS 会非常慢。
例如每个状态平均可以扩展出 b 个新状态,最短路径长度是 d,那么普通 BFS 大概会搜索:
数量级接近:
当 d 稍微大一点,状态数会爆炸。
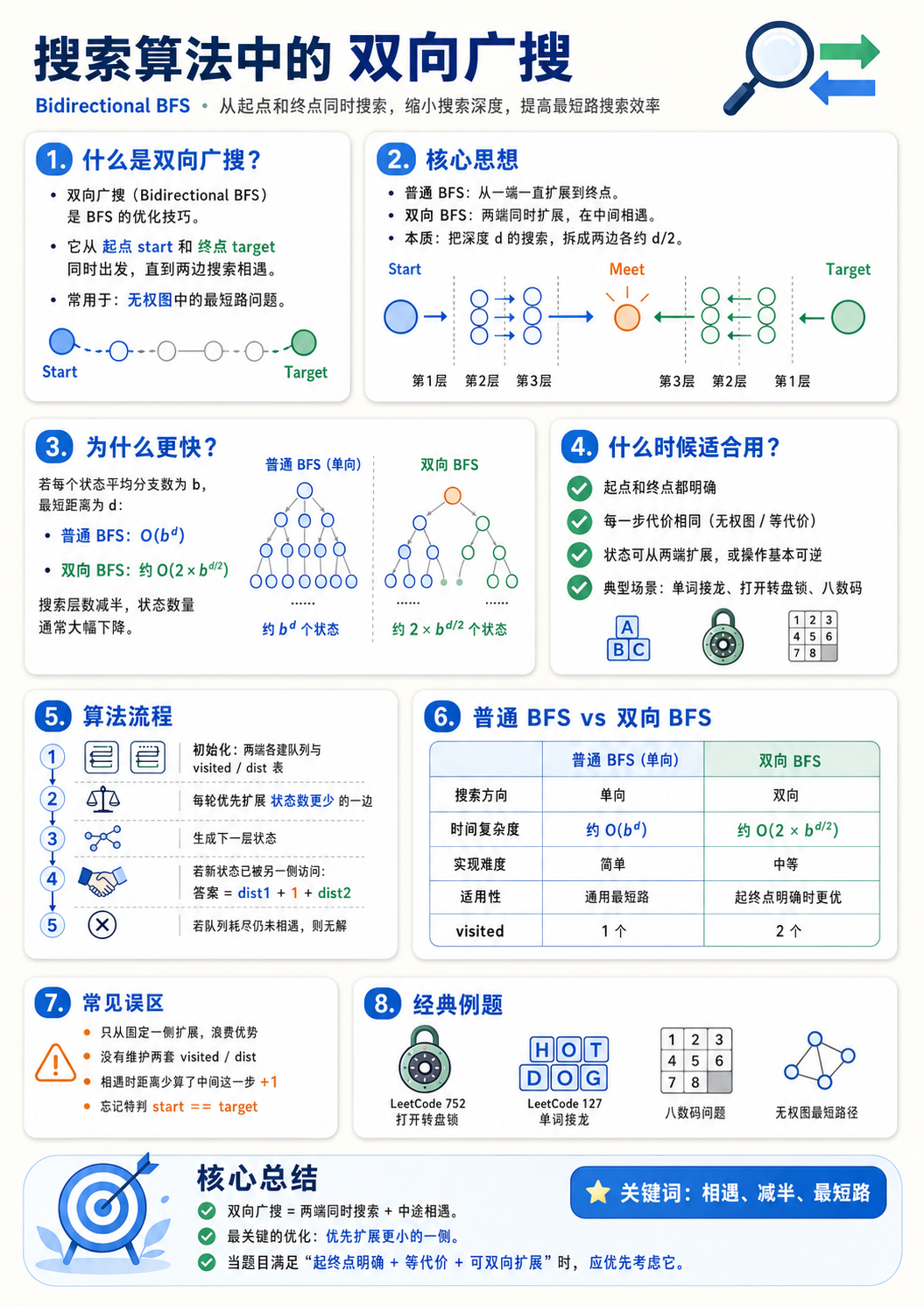
二、双向广搜的核心思想
1. 基本思想
双向广搜不是只从起点开始搜,而是:
一边从起点 start 向终点 target 搜
一边从终点 target 向起点 start 搜当两边搜索的区域相遇时,就说明找到了一条路径。
示意:
普通 BFS:
start -> -> -> -> -> -> target
双向 BFS:
start -> -> -> <- <- <- target
相遇2. 为什么双向 BFS 更快?
如果最短路径长度是 d,普通 BFS 需要从起点搜到深度 d。
双向 BFS 则大致只需要:
从起点搜 d / 2 层
从终点搜 d / 2 层复杂度从:
降低到近似:
这就是双向广搜最大的优势。
三、双向广搜适用场景
双向广搜适合以下问题:
1. 有明确起点和终点
比如:
start 状态明确
target 状态明确如果题目只问“能到达哪些点”,没有明确终点,就不适合双向 BFS。
2. 每一步代价相同
双向 BFS 本质仍然是 BFS,所以通常用于:
无权图最短路
每次操作代价相同如果边权不同,一般要考虑 Dijkstra、A* 等算法。
3. 状态可以双向扩展
也就是说:
能从 start 推出下一个状态
也能从 target 反向推出上一个状态有些问题的操作天然可逆,例如:
八数码
打开转盘锁
单词变化
图上的无权最短路有些问题反向扩展很困难,就不适合双向 BFS。
四、双向广搜的基本流程
双向 BFS 通常维护两组队列或集合:
正向搜索集合:从 start 出发
反向搜索集合:从 target 出发同时维护两个访问表:
visitedStart:记录从 start 到某状态的距离
visitedTarget:记录从 target 到某状态的距离算法流程:
1. 把 start 放入正向队列
2. 把 target 放入反向队列
3. 每次选择当前状态数量较少的一边进行扩展
4. 对当前层的每个状态生成 next 状态
5. 如果 next 已经被另一边访问过:
说明两边相遇
答案 = 当前距离 + 1 + 另一边距离
6. 如果两边搜索结束还没有相遇:
无解五、核心细节讲解
1. 为什么每次扩展较小的一边?
这是双向 BFS 的一个重要优化。
假设当前:
正向 frontier 有 10000 个状态
反向 frontier 有 20 个状态如果扩展正向,会生成大量新状态。
如果扩展反向,只需要处理很少状态。
所以双向 BFS 常用策略是:
每次优先扩展状态数量更少的一边这样可以显著减少搜索量。
2. 为什么需要两个 visited?
普通 BFS 只需要一个 visited。
双向 BFS 需要两个:
visitedStart:从起点搜索过的状态
visitedTarget:从终点搜索过的状态因为我们需要判断:
当前这一边生成的新状态,是否已经被另一边搜到过?如果搜到过,说明两边相遇。
例如:
start -> A -> B
target -> D -> C -> B当正向搜到 B,发现反向也搜到过 B,就可以合并路径。
3. 距离怎么算?
假设:
visitedStart.get(cur) = 从 start 到 cur 的距离
visitedTarget.get(next) = 从 target 到 next 的距离当前从 cur 扩展到 next,这一条边长度是 1。
如果 next 已经被另一侧访问过,那么总距离是:
visitedStart.get(cur) + 1 + visitedTarget.get(next)举例:
start -> A -> cur -> next -> X -> target如果:
start 到 cur 的距离是 2
cur 到 next 是 1
target 到 next 的距离是 2那么总距离:
2 + 1 + 2 = 54. 注意“边数”和“节点数”的区别
有些题目问的是:
最少操作次数通常答案是边数。
例如:
start -> A -> B -> target操作次数是 3。
但有些题目问的是:
路径包含多少个单词 / 节点例如 LeetCode 127 单词接龙,返回的是序列长度:
hit -> hot -> dot -> dog -> cog这里边数是 4,但返回值是 5。
双向 BFS 算出来的通常是最短边数。
如果题目要求节点数,最后可能需要 +1。六、双向广搜模板
下面这个模板适合讲通用状态搜索问题。
假设状态用 String 表示,比如:
"123450"
"hit"
"0000"import java.util.*;
public class BidirectionalBFS {
public int bidirectionalBFS(String start, String target) {
if (start.equals(target)) {
return 0;
}
// 从起点出发的距离表
Map<String, Integer> distStart = new HashMap<>();
// 从终点出发的距离表
Map<String, Integer> distTarget = new HashMap<>();
Queue<String> queueStart = new LinkedList<>();
Queue<String> queueTarget = new LinkedList<>();
queueStart.offer(start);
queueTarget.offer(target);
distStart.put(start, 0);
distTarget.put(target, 0);
while (!queueStart.isEmpty() && !queueTarget.isEmpty()) {
// 每次扩展状态数更少的一边
if (queueStart.size() <= queueTarget.size()) {
int ans = expand(queueStart, distStart, distTarget);
if (ans != -1) {
return ans;
}
} else {
int ans = expand(queueTarget, distTarget, distStart);
if (ans != -1) {
return ans;
}
}
}
return -1;
}
private int expand(
Queue<String> queue,
Map<String, Integer> curDist,
Map<String, Integer> otherDist
) {
int size = queue.size();
for (int i = 0; i < size; i++) {
String cur = queue.poll();
int curStep = curDist.get(cur);
for (String next : getNextStates(cur)) {
// 如果当前方向已经访问过,就跳过
if (curDist.containsKey(next)) {
continue;
}
// 如果另一方向访问过,说明两边相遇
if (otherDist.containsKey(next)) {
return curStep + 1 + otherDist.get(next);
}
curDist.put(next, curStep + 1);
queue.offer(next);
}
}
return -1;
}
private List<String> getNextStates(String state) {
List<String> nextStates = new ArrayList<>();
// 根据题目生成下一批状态
// 这里写具体逻辑
return nextStates;
}
}七、双向广搜的另一种写法:Set 写法
有些题目中,更常见的是用 Set 表示当前层。
这种写法在「单词接龙」里很常用。
Set<String> beginSet = new HashSet<>();
Set<String> endSet = new HashSet<>();
beginSet.add(beginWord);
endSet.add(endWord);每一轮扩展较小的集合:
if (beginSet.size() > endSet.size()) {
Set<String> temp = beginSet;
beginSet = endSet;
endSet = temp;
}然后生成下一层:
Set<String> nextSet = new HashSet<>();如果生成的新状态存在于 endSet 中,说明相遇。
这种写法代码更短,但是不如 Map<String, Integer> 距离表清晰。
初学者建议先掌握 Map + Queue 写法。
熟练之后可以使用 Set 层序写法优化代码。八、双向广搜和普通 BFS 的对比
双向广搜
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
评论交流
欢迎留下你的想法