


现在比较流行的词向量学习方法有Word2Vec、GloVe等,并且把这些词向量作为一些下游任务的初始化可以提升模型的性能。但是一个词的向量表示,不应该是一成不变的,而应该根据它所处的“上下文环境”动态生成。
CoVe
在图像识别领域,研究者经常把ImageNet上预训练的CNN用于其他图像识别模型。那么在NLP中,也可以把一个任务中训练好的模型用于另外一个任务。基于这样的想法,作者提出了将context vectors(CoVe)添加到原有的模型中的方法,并且通过实验证明在常见的NLP任务,例如情感分析、问题分类、推理和问答等,都起到了提升性能的作用。
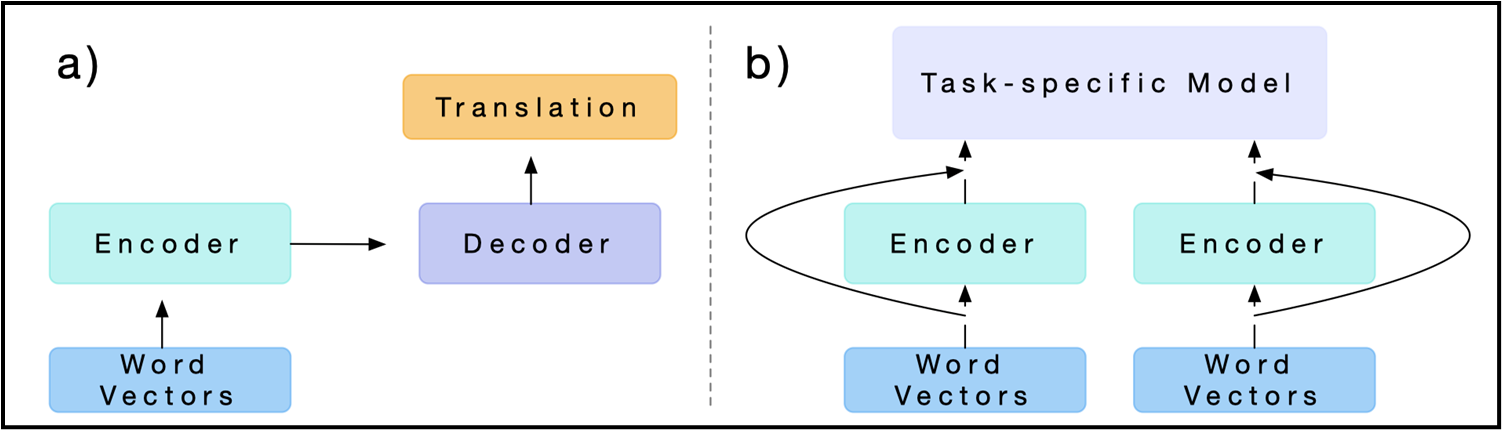
a) 机器翻译预训练阶段 (Pre-training)
流程:
Word VectorsEncoderDecoderTranslation详解:
底部的
Word Vectors:这通常是静态词向量(比如 GloVe)。模型先把输入的英语句子转换成 GloVe 向量。中间的
Encoder:这是一个深层的双向 LSTM 网络。它学习句子中词与词之间的上下文依赖。顶部的
Decoder和Translation:解码器将编码器的输出翻译成目标语言。
目的: 这个阶段的唯一目的,就是利用庞大的双语翻译数据,把中间这个浅绿色的
Encoder训练成一个“极其懂上下文语义”的特征提取器。训练完成后,Decoder就完成使命,被直接丢弃了
b) 下游任务微调阶段 (Downstream Application)
流程:
Word Vectors+Encoder输出Task-specific Model详解:
现在我们面临一个新的具体任务(比如情感分析),网络顶部变成了紫色的
Task-specific Model(下游特定任务模型)。我们依然先用底部的
Word Vectors(静态 GloVe)把新句子转化为基础向量。接着,这些基础向量被送入我们在阶段 a) 训练好并保留下来的
Encoder中。此时Encoder输出的,就是带有浓厚上下文语境的 动态 CoVe 向量。最核心的细节(看那两条绕过去的弧形长箭头): 图中有一条弧线直接从底部的
Word Vectors绕过了Encoder,直通顶部的Task-specific Model。同时,Encoder的输出也指向上方。这表示,输入到下游任务模型的特征并不是单一的,而是将静态的 GloVe 向量和动态的 CoVe 向量进行了拼接(Concatenation)。
模型实现
在海量英德双语语料上,我们训练一个带注意力机制的 Seq2Seq 模型。
Step 1: 静态特征注入 (Input & Static Embedding)
给定源语言(如英语)句子 。
网络首先通过预训练的 GloVe 词表查表,将其映射为底层的静态向量表示:
Step 2: 动态特征提取 (MT-Encoder 编码)
将静态向量序列 送入双向 LSTM 编码器。这一步计算出的全局隐藏状态矩阵(包含了各个时间步的),就是未来我们要提取的 CoVe 向量:
Step 3: 上下文注意力聚焦 (Attention-based Decoder)
为了逼迫 学到精准的语义,解码器需要通过注意力机制不断去“审视”它。
计算当前解码状态 对整个编码矩阵 的注意力分布概率:
利用分布概率 对 进行加权求和(提取上下文向量),并与当前解码状态拼接,经过 激活得到融合状态:
结合目标语言的真实词输入 ,更新下一步的解码器隐藏状态:
Step 4: 翻译目标预测 (Output Layer)
利用融合了全局上下文的 ,预测目标语言(如德语)下一个词 的概率分布。通过反向传播不断优化网络参数。
当上述翻译模型训练收敛后,我们进入下游具体任务(如情感分析、命名实体识别)的应用阶段。
Step 5: 截断网络 (Truncation)
直接丢弃 Step 3 和 Step 4 中的整个 Decoder 结构和输出层,只保留 Step 2 中训练好的 编码器,并冻结其参数(不再更新)。
Step 6: 终极融合拼接 (Final Integration)
面对下游任务输入的一个全新句子序列。
重复 Step 1,查表获取它的静态基础向量:$\text{GloVe}(w)$
将其送入冻结的编码器,获取融合了当前语境的动态输出:$\text{CoVe}(w) = \text{MT-LSTM}(\text{GloVe}(w))$
最终输出: 将静态特征与动态特征在特征维度上进行直接拼接,作为下游特定任务模型(Task-specific Model)的
Embedding层输入:
缺点
1. 语料获取难,模型性能受限数据
受限双语平行语料:获取成本极高,数据量被彻底锁死,无法利用海量的互联网无监督纯文本。
通用性极差:双语数据通常局限于特定领域(如官方新闻、议会记录),导致模型像个“偏科生”,覆盖的领域有限,缺乏广泛的通用自然语言常识。
2. 核心能力不足,性价比低
实验表明,如果抛弃底层的 GloVe,仅仅使用 CoVe 提取出来的动态特征去跑下游任务,效果其实很平庸。
它最终依然需要和传统静态词向量搭配(强行拼接)才能看到显著提升。这证明机器翻译的 Encoder 并没有学透词汇的全部特征,只能作为 GloVe 的一个昂贵“辅助”。
双向语言模型(BiLM)。
BiLM 的精妙之处在于,它用两套独立运转的单向 LSTM,同时从两个方向对同一个句子进行语言模型建模:
1. 前向语言模型 (Forward LM)
任务: 根据目标词 之前的历史上下文,来预测当前词 的概率。
数学表达:
内部计算: 在第 步,前向 LSTM 输出隐藏状态 。
2. 后向语言模型 (Backward LM)
任务: 将句子完全反转。根据目标词 之后的未来上下文 ,来反推当前词 的概率。
数学表达:
内部计算: 在第 步,后向 LSTM 输出隐藏状态 。
3. 联合优化目标 (Joint Objective)
BiLM 并不是简单地把两个模型分开训练,而是将它们绑定在一起,最大化这两个方向的联合对数似然概率。
模型的最终损失函数(取负号进行最小化)的核心公式如下:
ELMo
深层神经网络的不同层,学到的语言知识是完全不一样的。
ELMo 的底层通常是一个基于字符的卷积网络(Char-CNN),上面叠加两层双向 LSTM(即 的 BiLM)。
对于输入句子中的一个词 ,ELMo 会提取它在网络中所有层的内部状态:
(底层 Char-CNN):提取的是词法特征(如词缀、大小写)。因为是基于字符级输入的,所以 ELMo 彻底解决了 Word2Vec 和 CoVe 遇到未登录词 (OOV) 就瘫痪的痛点!哪怕是没见过的火星文,它也能拆成字母拼出个向量来。
(第一层 Bi-LSTM):提取的是句法特征(Syntax),比如这个词是名词还是动词(词性标注)。
(第二层 Bi-LSTM):提取的是高级语义特征(Semantics),比如“apple”在这里是水果还是公司 (词义消歧)。
既然每一层都有好东西,下游任务(比如情感分析、机器翻译)该用哪一层呢?
ELMo 的回答是:我全给你,你自己按需分配权重。
在应用到特定下游任务(Task)时,ELMo 会学习一组专属的参数,将所有层的状态进行线性加权求和。
公式极简拆解:
:词 在第 层的隐藏状态向量。
:Softmax 归一化权重。 这是下游任务自己学出来的。如果下游任务是“词性标注”,模型就会自动给 (句法层)分配极高权重;如果是“阅读理解”,就会给 (语义层)分配极高权重。
:全局缩放系数。 用来根据下游任务的特性,放大或缩小 ELMo 向量的整体幅值,以配合下游网络自身的结构。
动态词向量预训练模型
本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
评论交流
欢迎留下你的想法