什么是算法
算法:简单来说,算法就是通过一系列的计算步骤,用来将输入数据转换成输出结果。
算法的性质
有穷性:算法必须在有限步骤内结束,且每个步骤在合理时间内完成,避免无限循环。
确定性:每一步指令含义明确、无歧义,相同输入必得相同输出。
可行性:所有操作可通过基本运算(如加减、逻辑判断)在有限次内实现。
输入:算法有零个或多个输入,取自特定对象集合(如用户数据或初始值)。
输出:至少有一个输出,反映输入加工后的结果(如计算结果或状态)。
算法的正确性
正确性:一个算法是正确的,如果它对于每一个输入都最终停止,而且产生正确的输出。
正确性的证明方法
循环不变式
三步法:初始化(循环前成立)→ 保持(一次迭代后仍成立)→ 终止(循环退出时结合不变式推出规格)。
例题
用循环不变式证明一下算法正确性:

循环不变式:
在第 次迭代开始时(即尚未处理 之前),变量 等于前缀 的最大值:
Step1:初始化
循环第一次迭代前 ,此时 ,显然:
不变式成立。
Step2:保持
设在某次迭代开始时不变式成立,即:
现比较 与 :
若 ,执行 ,此后
若 ,不更新,仍有
因此本轮结束时, 成为前缀 的最大值,下一轮开始时索引变为 ,于是:
不变式对下一轮仍成立。
Step3:终止
当循环结束时, 。根据不变式,循环结束时刻 等于:
也就是数组整体最大值。返回 即满足规格(部分正确性)。
算法时间复杂度的估算
渐进复杂度
上界
如果 ,即 的数量级小于等于
下界
如果 ,即 的数量级大于等于
紧确界
如果 ,即 的数量级等于
严格
例题1

定义:若存在常数 、 使得对所有 , ,则 。
(1)证明 :
当 时,有 ,且 ,于是
取 , ,满足定义,故 。
(2)证明 :
当 时,有 , , ,于是
取 , ,满足定义,故 。
例题2
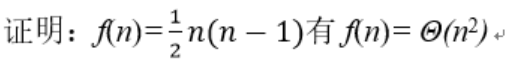
取
下界:
上界:
于是存在常数 , , 使得
故
递归算法时间复杂度计算
递归方程
步骤:
定义T(n):表示问题规模为n时的时间复杂度。
拆分递归过程:分析每次递归调用的子问题规模和操作次数。
建立递推方程:将T(n)表示为子问题的时间复杂度之和。
求解方程:通过代入法、递归树或Master定理得出结果。
递归树
步骤:
画出递归树:每个节点表示一个子问题,标注其规模和操作次数。
计算每层的时间复杂度:将每层所有节点的操作次数相加。
累加所有层的复杂度:得到总时间复杂度。
例题
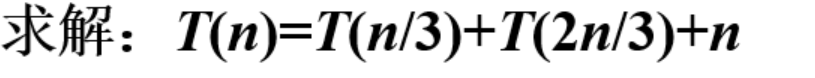
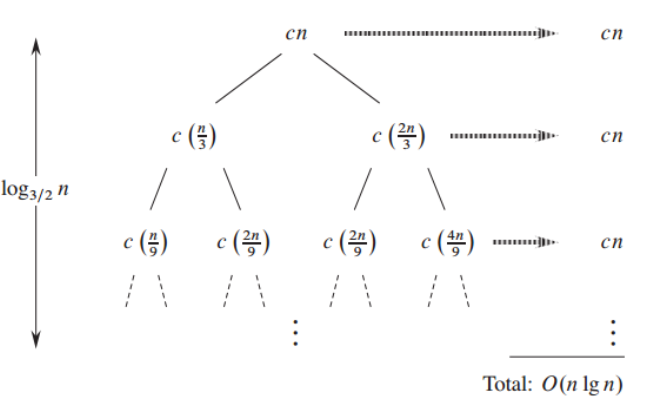
每一层把规模 分成 和 。从根到叶的最长路径总是走“更大的那支” :
设第 层所有子问题规模之和为 。根层 。
把某个规模为 的结点拆成 和 后,新层的总规模贡献仍是 。
对每个结点都如此,故
归纳得 每层 。而本题每个结点的“合并/额外代价”与子问题规模成线性(记常数为 ),
所以第 层总代价是 。
层数约为 ,于是内部结点总代价
叶子层:每个叶子规模 ,叶子个数不超过同层规模之和 ,
总叶子代价 ,被 主导。
结论:
主定理
适用条件:递归方程形如 ,其中:
:子问题的数量
:每个子问题的规模缩小因子
:分解和合并子问题的时间复杂度
结论:
若 ,即 ,有 ,则
若 ,则
若 ,即 ,有 ,且对 与所有足够大的 ,有 ,则
例题

(1)这里 , ,
比较 与 则
故
(2)这里 , ,
比较 与
故



评论交流
欢迎留下你的想法